The range is a descriptive statistic that is commonly used in reports, data dashboards, and more.
It measures the spread of the data, calculated by taking the difference between the lowest and the highest values in the data set.
Refresh your understanding of what the range is, learn the answers to a couple of frequently asked questions about the range, and a couple examples of how the range can be useful by watching the video below or continue to read the rest of this post.
As discussed in the video above, one frequently asked question about the range is if it is the same as the standard deviation. The answer to that is no, it is not. The standard deviation is how far the values are from the mean or average of the data set while the range is the difference between the lowest and the highest values in the data set.
Another frequently asked question is if the range could be a negative number. The answer to that is no, it can not be a negative number. It will either be a positive number because it is the difference between the highest and lowest values or it will be zero if all the numbers are the same in the data set.
One example of how the range could be useful is identifying outliers that are data entry errors in a health study.
Another example would be looking at the range of shipping costs using different packaging materials for an e-commerce store.
The above video goes into more detail for each of those two examples.
Refreshing your understanding of the range can help you to be more prepared to review and better understand data reports or dashboards including this descriptive statistic.
What is an example of how using the range would be useful in a data set from your work or in your life?
Understanding the mode is important. The mode, or the most occurring value in a data set, is a commonly used descriptive statistic that is especially useful when working with nominal or categorical data.
The video below provides a brief overview of what the mode is, answers to frequently asked questions (FAQs) about the mode and gives real world examples of using the mode.
The mode is different than the mean (average) and median. The mode is the most occurring value whereas the mean is the sum divided by the number of observations in the data set and the median is the middle number in the data set when the data is put into order by size, from smallest to largest.
All of the data in the data set has to be in or converted to the same unit of measurement in order to find the mode.
There can be more than one mode in a data set. Some data sets may have multiple values that occur the most.
Watch the above video to see how the mode is used to find the state(s) with the most customer orders in the e-commerce store example, and how it’s used to in the plant nursery/garden store example to identify the type of flower or plant that survey respondents like to give as gifts.
In conclusion, the mode is useful in a variety of different types of data sets in a variety of different scenarios across many industries. Refreshing your understanding of this basic descriptive statistic will help you use it in ways that are useful to you and your organization.
Do have any examples of how the mode is useful in analyzing data for your work or in your life? Share your example in the comments below!
Data and research can be very useful in making goals more specific using a data-informed SMARTER goal setting process.
SMARTER is an acronym for setting goals. Different organizations or individuals prefer slightly different words that make up the acronym, the most commonly used words are included below.
S = Specific
M = Measurable or Meaningful
A = Actionable, Achievable, Attainable, or Action-Oriented
As the video below discusses, making goals specific involves specifying the what, how, why, who, and/or where part of the goal.
As discussed in the above video, data can help provide actual, specific numbers of how your organization is currently doing in certain areas and provide a way to measure improvement as specified in the specific goal(s).
For example, marketing metrics such as the click through rate for ads, social media engagement rate, email open rate, data on customer demographics, and other such metrics are probably ones that your organization already measures and can give you very specific data on how well your organization is doing in these specific areas.
Research can provide additional insights such as emerging trends in your organization’s industry to use as a benchmark for your organization to strive towards. Additionally research can provide additional insights on the who, what, where, or how factor of the goal(s).
When using data and research to help set more specific goals it is important to keep several things in mind.
For one it is important to understand the data sources as well as the data sources’ limitations on how specific of data they can provide. The data can only be as specific as it is collected or entered into the data source. This also means that the goal can only be made as specific as you or your organization can find or create a data source to measure that data point as specifically as your organization would need it to be in order to track that goal.
For example, if using geographic data to track a goal such as increasing the number of customers in a specific city, the data source would have to provide the data at that same city level, not at the state or country level.
Also, it is important to specify units of measurement. For instance, a goal of increasing something by 5 times is a lot different than increasing it by 5%.
Additionally, it is important to know which units of measurement are provided in the data and which units would have to be calculated. For example if the data source provides time in minutes but the goal deals with time in hours, then a calculation will have to be done to convert minutes to hours.
Factoring in the time and/or resources it will take to measure progress towards the goal(s) with how specific that goal is or those goals are is another important thing to keep in mind. You want the goals to be as specific as it will be useful for them to be, but not too specific or more specific than is really needed. You do not want to waste time and/or resources tracking and calculating data to measure progress towards the goal(s) that is more specific than it needs to be.
RILLIAN is a consulting agency focused on Research & Insights Leading to Learning, Innovation And actioN (R.I.L.L.I.A.N).
If you or your organization needs assistance and support involving any of the above to achieve your goals, or if you or your organization is in need of assistance in setting and tracking your goals using data-informed or data-driven methods, contact us and let’s getting working on that together! Schedule a meeting, learn more about us, connect with us on LinkedIn, or watch our Three Minute Tuesday/Thursday video series on our YouTube channel.
Google Sheets can be used to calculate descriptive statistics for small data sets. However, with large data sets we recommend using statistical software made for analyzing large data sets, such as R, Tableau, SAS, STATA, SPSS, and other such software.
In the video below, we show how to calculate these seven descriptive statistics.
Mean (Average)
Median
Mode
Range
Standard Deviation
Coefficient of Variation
Z-Score
In conclusion, Google Sheets can be used to quickly and conveniently calculate descriptive statistics like the seven discussed in this article when working with small data sets.
Adding filters in Tableau helps you make your Tableau dashboards more useful. Filters allow you to display subsections of your data set in your dashboard.
One way to add a filter is to use one worksheet that you have in the dashboard as a filter for the other worksheets. To do this, select the filter icon in the menu that appears to the right of the worksheet when you have that worksheet selected.
Another way is to go to the drop down menu to the right of the worksheet, hover over “Filters”, which then brings up a drop down menu in which you can select which of the variables in the worksheet you want to use to filter by.
The video below shows how to do both of these methods for adding filters in less than 3 minutes.
As shown in the above video, adding filters to your Tableau dashboards can make your dashboards more useful and easier to display a selected subsection of your data set.
Avoiding these 4 things in data spreadsheet column titles, as discussed in the quick (3 minute and 38 second) video below and in this post, will make it easier to analyze the spreadsheet data using programs like R or SAS or importing the spreadsheet data into a database.
(1) Avoid fancy formatting
Avoid fancy formatting in the column headers when the spreadsheet is going to be imported into a program such as R or SAS for analysis.
Fancy formatting such as making words bold, italic, or adding colors can cause errors or even prevent the data from being able to be imported until the formatting is reverted back to plain, unformatted column headers.
Watch the video above to see examples of fancy and plain column headers.
Avoiding using fancy formatting in the first place will save your consultant or analyst time from having to change the formatting back to plain.
(2) Avoid inconsistent naming conventions
Avoid inconsistent naming conventions for titles and also avoid using special characters such as exclamation points(!), asterisks(*), at symbols (@), and other such symbols in the title of the column header.
For one it can be confusing. Also, special characters in the titles can cause errors in analysis or importing the data into a database.
For an example of a spreadsheet using inconsistent naming conventions and special symbols in the column headers watch the video above.
(3) Avoid using really long descriptive titles
Avoid using long descriptive titles with spaces in between the words. Shorter titles are easier to analyze. Some software programs can’t recognize titles that have spaces between the words as variables. This will result in error messages or a failure to import the data.
Shorten the titles using codenames for those variables.
For an example of really long descriptive titles being shortened into code names, watch the video above.
Shortening codenames leads to the 4th thing to avoid in column title headers:
(4) Avoid forgetting to include a code book or some kind of documentation of what code names you shortened the long descriptive titles into
Don’t forget to include a code book or other similar documentation for long descriptive column titles that you’ve shortened the name of.
When working with a team no one else will necessarily know what that code title means and if you don’t document it somewhere, then you may even forget what it was yourself.
By avoiding fancy formatting, inconsistent naming conventions, using really long descriptive titles, and forgetting to include a codebook or other documentation you will make it easier and more efficient to analyze the spreadsheet data using programs like R or SAS or importing the spreadsheet data into a database.
When using of Google Sheets, you may wonder if it’s possible to use SQL query language to pull up data in Google Sheets, especially when working with large data sets. The answer is yes, it is possible!
Here is a video below giving examples using the below formula with three different types of Google Sheets sample data sets created by RILLIAN.
Formula:
=QUERY(data, query, headers)
Three Minute Tuesday are a video series by RILLIAN, a consulting agency, briefly, in approximately 3 minutes or less, cover a topic related to work involving Research & Insights Leading to Learning, Innovation, And actioN (R.I.L.L.I.A.N.).
One sample data set is an e-commerce store sample data, the second is an epidemiology infectious waterborne disease and exposure sample data set, and the third is a sample videographers log data set.
One type of data that this is useful with is e-commerce data. E-commerce data, like the sample data set shown in this video, has tons of information, all of which is useful in the operations of the store, but looking at all of it can be a little overwhelming. Using the SQL query code above, specific data that you want to look at can be pulled into a separate sheet in the Google Sheets workbook. As you can see in the video, using SQL to do a data query makes it easier to see in which states a certain product, Baby Yoda t shirts, are selling the best in.
Another example is querying data from an epidemiological sample data set. This data set has 2,000 rows with two columns of data. The first column has data on if the person has a confirmed diagnosis of a waterborne disease or not. The second column has data on exposure; if the person had the exposure of swimming in a body of water of interest in this study or if they did not have the exposure. The number one is used to indicate yes and the number zero is used to indicate no.
Using SQL, data can be queried to only pull those who had the diagnosis and had the exposure into a separate sheet in the Google sheets workbook.
Or if you were interested in looking at those who had a confirmed diagnosis but didn’t have the exposure, just change the one to zero, and you can simply adjust the formula and the data query pulls those cases up instead.
A third sample data set is a videographer’s video log. This has all kinds of data that is useful to the videographer, but when just wanting to look at a couple things in the data, such as the take number of a video clip (takes are the number of times that scene was filmed to get it to be just right), it can be useful to do a data query and pull that data into a separate sheet in the Google sheet workbook, as shown in the video.
As you can see, there are many ways this type of data query language can be useful in a variety of different types of data sets in Google Sheets.
Have you used SQL in Google Sheets? What kind of data set did you analyze? Did you find SQL to be helpful for the data set you were working with?
Population data and the percent change in population are two demographic measures that are great to look at for a variety of different reasons.
There are many different ways to visualize these two measures, depending what it is that you want to learn from this data or show to others in a presentation. In this post and in the video we demonstrate two different ways to do so using Tableau.
One way is to display the population data on a map. This is helpful especially if geography is important to what you are working on with this population data. For example if you are presenting different population sizes of different cities to a group of stakeholders who are not familiar with the locations of those cities or how far away or close to each other they are, then visualizing this on a map for them can help show this to them.
The percent change in population can also be visualized on a map. However, a better way to show percent change in population could be a bar graph.
The second way to display population data is with a bar graph, such as the bar graph shown in the video below for population change in 5 East Coast cities of Atlanta, Boston, New York City, Richmond (VA), and Washington D.C.
As you can see in the video, the interactive bar graph created using Tableau makes it easier to see which city had the greatest population change over the two five year periods looked at in this data set.
Three Minute Tuesday Videos by RILLIAN, a consulting agency, briefly cover a topic in approximately 3 minutes or less. These videos are provide brief overviews of topics that are useful for anyone working in the areas of Research & Insights Leading to Learning, Innovation, And actioN (R.I.L.L.I.A.N.).
Are there any helpful tips you would like to add about visualizing population data or population change data in Tableau?
Do you have any suggestions for topics you would like to see us cover in our Three Minute Tuesday videos?
Email Jillian at Jillian.Regan@RILLIANconsulting.com .
Six Sigma is a quality improvement methodology that organizations in many different fields utilize to improve their organization’s processes and performance.
A systematic way for keeping track of Six Sigma projects is essential to being able to effectively use Six Sigma to improve the processes and performance of the organization. It is also important that this system is standardized throughout the organization and that all employees who will be using it are trained on how to correctly use it.
A good system will include a way to decide if the problem identified is enough a problem to be addressed in a Six Sigma project, before proceeding to conducting a Six Sigma project. In addition there should be a way to track both the impact of the problem and solution on the customer (voice of the customer) as well as on the business (voice of the business). It is important to document attributes of the data that is to be collected, such as if it is ordinal scale or nominal scale, to make it easier to keep track of which types of statistical analysis are appropriate to apply to the data.
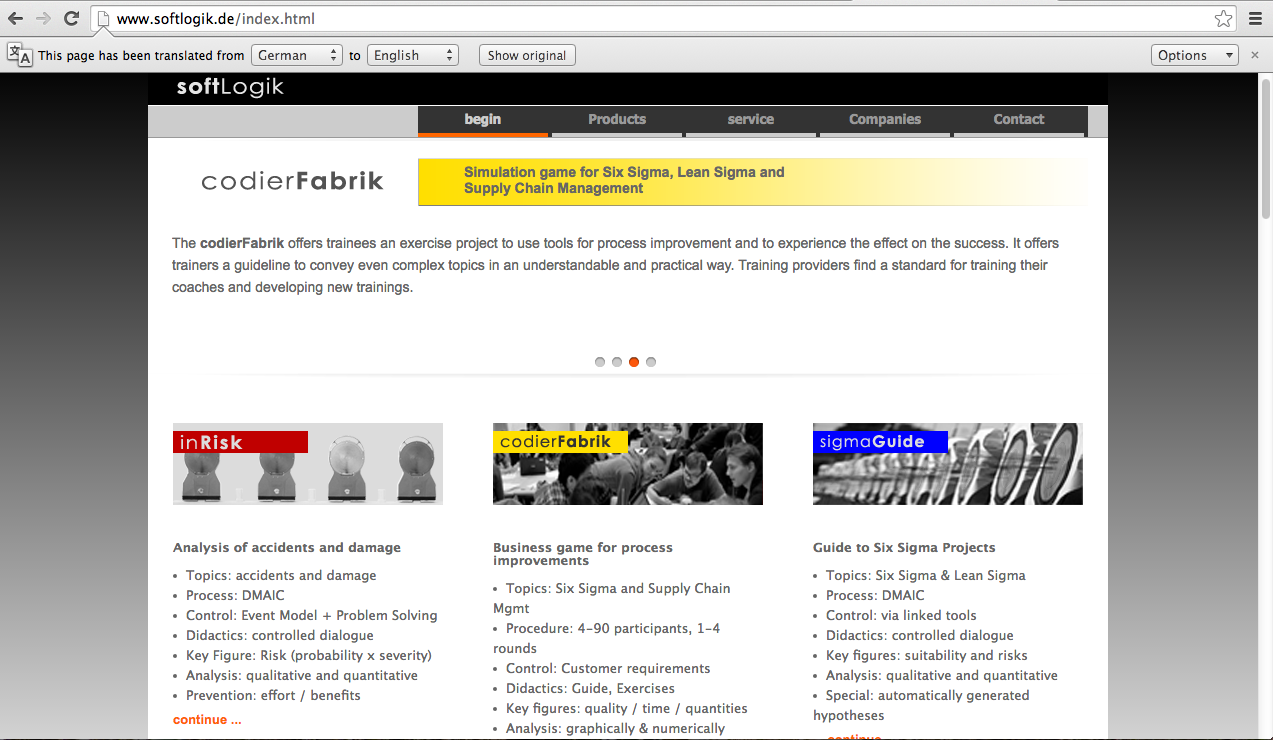
One way to have a good system for Six Sigma projects could be to use a software program specifically designed for this, such as SixSigma Guide. SixSigma Guide is a software guide designed specifically for Six Sigma Projects.
The homepage for SoftLogic, with SixSigma guide on the far right and two other software programs on the left and middle.
About SixSigma Guide:
It was created by Dr. Reiner Hutwelker
He is a business consultant,
Master Black Belt in Six Sigma,
and an adjunct professor at Hochschule für angewandte Wissenschaften München and Management Center Innsbruck in Eresing, Germany.
Note: this software tool does not provide the statistical analytic capabilities needed in most Six Sigma projects, so a statistical software program like R, SAS, Minitab, or Stata can be used for statistical analysis of the data in conjunction with this software tool
Review of SixSigma Guide:
This software is a useful and practical tool, although it may not be the right fit for every organization. It was clearly developed by a Master Black Belt in Six Sigma who used his many years of practical experience in conducting Six Sigma projects as well as in educating future Six Sigma quality improvement professionals. This software is relatively easy to learn how to use for people who are familiar with other software like Microsoft Excel. One of the best things about it is that it walks the user, step by step through the whole Six Sigma DMAIC (Define, Measure, Analyze, Improve, Control) cycle. Instead of having all these steps and sub-steps saved in different spreadsheets in folders on a shared drive, with this software, everything can be kept track of in one place.
While it is functional and relatively user friendly, I feel that in order to be more marketable the design of the user interface might need to be enhanced. While it is perfectly functional, people have become used to seeing beautifully designed software programs. Large organizations may also wish to be able to customize it with their logos and branding when implementing it across the organization.
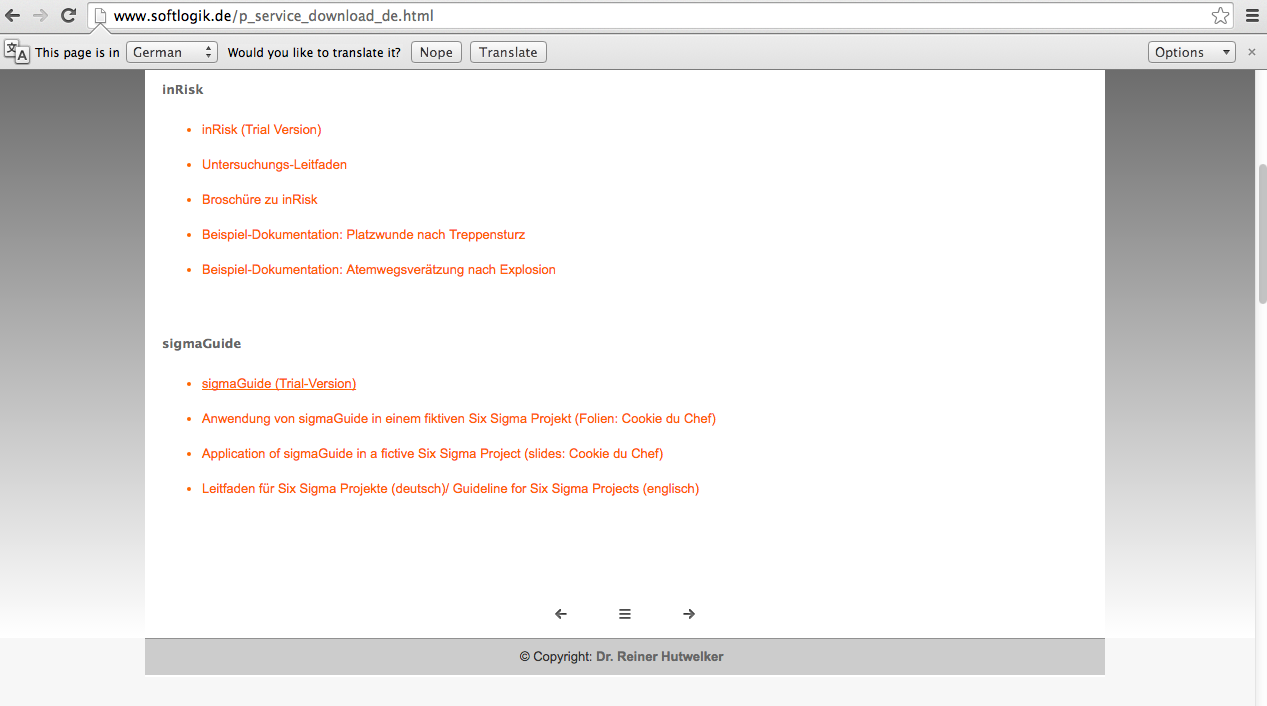
A screenshot of the download page to download the SixSigma Guide software. The option to download the free trial is listed first. Both English and German slides with examples of using the software for a Six Sigma project are linked below the download link.
Another way could be to use a combination of different types of software the organization is currently using, such as Microsoft Excel or Google Docs, combined with a file sharing system, such as a server or cloud based storage solution, such as DropBox, so that all stakeholders who need access to the projects can easily access it.
Whichever systems and software you choose to use, it is essential that it there is a systematic and standardized way of conducting and keeping track of Six Sigma projects across your organization.
I’d love to hear your thoughts! Have you used SixSigma Guide software or a similar software for Six Sigma projects? What do you think about it?
Disclaimer: This is an independent review of software, I am not sponsored in anyway by any of the software companies or individuals listed or reviewed in this article. None of the links are affiliate links. I am just sharing my thoughts about software that could be useful for Six Sigma projects. I learned of this software while taking an online course on Six Sigma, from the Technical University of Munich (TUM) in Germany and edX.org, in which Dr. Hutwelker was a guest lecturer.
Jillian Regan, MPH is a consultant at Rillian. She enjoys quality improvement using data to improve processes within the organization, so that the organization can better serve its clients, customers, patients, or others. Connect with her by email at Jillian.Regan@RillianConsulting.com or Twitter (@JillianReganMPH) or LinkedIn.
Follow Rillian on Facebook to get updates on articles like this one or updates about current projects, like a bicycling survey!
In the information age, organizations and departments within organizations often encounter the problem of data existing in silos, where one department or organization cannot easily access data that they need for a project from another department or organization. This can lead to inefficiencies, such as having to stop a project and use time and resources just to retrieve the data needed before the project could continue.
Keep in Mind the Goals for the Data Project
It is important to keep in mind the organization’s problem or goal which the data project needs to measure or address.(1) Focus on that first instead of seeing what data may already be available. While it could be more time and resource intensive, the goal of the project may require new data to be collected because there is not existing data that meets the needs of the project.
Support from the Top and From All Involved
The executive team should be supporting and leading the effort as well as involving the managers of each department.(1) Also, staff involved in all levels of data collection, data entry, and data analysis should be aware of and involved to some degree in the organization’s effort to reduce data silos. Other staff who may not be directly involved in inputting the data should also be made aware of and engaged to some degree in the process of reducing data silos.
Make a New Framework for Data Collection
After breaking down silos, or when collecting new data, make a plan or framework for how the data can be integrated for all the stakeholders so that new data silos are not created.(2) For example instead of separate data files being stored on separate computers, have a shared drive that can be accessed by those who need access to that data across departments or organizations. (3)
Training and Relationship Building
Enhancing knowledge of other’s data needs and increasing trust between people from different departments or organizations is key to breaking down data silos and improving data sharing.
Workshops and learning lunch events are one way to do this. These bring people together to learn about what other departments, organizations, or projects needs, as well as create an atmosphere where people can connect with one another and improve their working relationships. (3)
Documentation is Key
Keep track of data sources, i.e. where the data came from. This is vital to understanding the data. This will also make it easier to know where to go to get updated data as needed. It is also essential to do when having teams of people working on the data project, so that everyone will be on the same page.
Have a system for keeping track of the person or persons to reach out to for specific data and their contact information who may be in a different department, on a different team, or from another organization.
Breaking Down Data Silos Across Different Research Topic Areas
A recent study included a collaboration with multiple sectors: researchers, a children’s hospital, and a police department to use sources of data–spatial video and geographic information systems (GIS)–that was able to provide insights into two different research topic areas–active school transport (AST) and child injury research– in which the data was usually siloed in different research projects.(4)
State Government Initiative for Open Data Portal
The state government of Virginia (in the United States) has an initiative of creating an open data portal, Data VA, of non-sensitive, public information that is made freely available for public use in an easily readable format.(5) At Datapalooza 2017, Virginia Secretary of Health and Human Resources, Bill Hazel, spoke about the need for the different sectors of state government to need to go horizontally across sectors in order to best be able to serve people because no one person whom they serve only fits into only one of the sectors. (6) He also spoke about the need for ethical use of data for a public purpose.
Breaking down data silos can allow organizations or departments within organizations to access data that will provide valuable insights into their organizations. This article presented a few ways in which to do this.
I’d love to hear from you about your ideas! Has your organization or department had success in breaking down data silos? What are some of the ways in which they were able to do this?
Schuch L, Curtis JW, Curtis A, Hudson C, Wuensch H, Sampsell M, Wiles E, Infantino M4, Davis AJ. Breaking Out of Surveillance Silos: Integrative Geospatial Data Collection for Child Injury Risk and Active School Transport. J Urban Health. 2016 Feb;93(1):36-52. doi: 10.1007/s11524-015-0006-9. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4794455/